扫二维码与项目经理沟通
我们在微信上24小时期待你的声音
解答本文疑问/技术咨询/运营咨询/技术建议/互联网交流

在图论中,拓扑排序(Topological Sorting)是一个有向无环图(DAG, Directed Acyclic Graph)的所有顶点的线性序列。且该序列必须满足下面两个条件:
1、每个顶点出现且只出现一次。
2、若存在一条从顶点 A 到顶点 B 的路径,那么在序列中顶点 A 出现在顶点 B 的前面。
有向无环图(DAG)才有拓扑排序,非DAG图没有拓扑排序一说。
实现拓扑排序一般有两种思路,一种基于贪心,一种基于深度优先搜索。接下来分别介绍这两种思路:
1、贪心
如图:
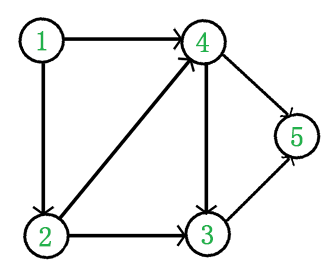
它是一个 DAG 图,那么如何写出它的拓扑排序呢?这里说一种比较常用的方法:
1、从 DAG 图中选择一个 没有前驱(即入度为0)的顶点并输出。
2、从图中删除该顶点和所有以它为起点的有向边。
3、重复 1 和 2 直到当前的 DAG 图为空或当前图中不存在无前驱的顶点为止。后一种情况说明有向图中必然存在环。
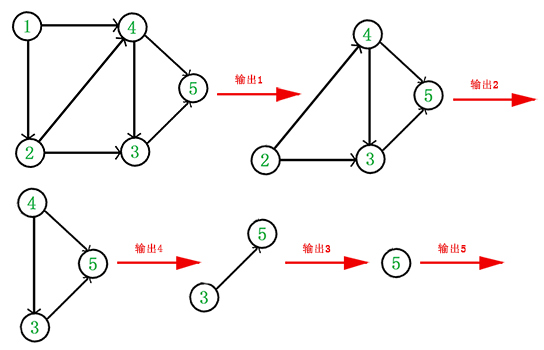
于是,得到拓扑排序后的结果是{ 1, 2, 4, 3, 5 }。
通常,一个有向无环图可以有一个或多个拓扑排序序列。
参考链接:拓扑排序(Topological Sorting)
伪代码:
TOPOLOGICAL-SORTING-GREEDY(g)
let inDegree be every verties inDegree Array
let stack be new Stack
let result be new Array
for v equal to every vertex in g
if inDegree[v] == 0
stack.push(v)
end
while stack.empty() == false
vertex v = stack.top()
stack.pop()
result.append(v)
for i equal to every vertex adjacent to v
inDegree[i] = inDegree[i] - 1
if inDegree[i] == 0
stack.push(i)
end
end
return result.reverse()
时间复杂度:Θ(V+E),V表示顶点的个数,E表示边的个数。
2、DFS(改良)
伪代码:
DFS-IMPROVE(v,visited,stack)
visited[v] = true
for i equal to every vertex adjacent to v
if visited[i] == false
DFS-IMPROVE(i,visited,stack)
end
stack.push(v)
DFS(改良)一个有用的特点是,对于两个顶点A、B,存在A到B的路径,而不存在B到A的路径,则从记录的顺序中取出的时候,一定会先取出顶点A,再取出顶点B。
利用此特性,我们可以这样实现拓扑排序:
伪代码:
TOPOLOGICAL-SORTING-DFS(g)
let visited be new Array
let result be new Array
let stack be new Stack
for v equal to every vertex in g
if visited[v] == false
DFS-IMPROVE(v,visited,stack)
end
while stack.empty() == false
result.append(stack.top())
stack.pop()
end
return result
时间复杂度:Θ(V+E),V表示顶点的个数,E表示边的个数。
此方法相比贪心而言,最大的缺点是:无法检查图中是否存在环路。
如何解决这个问题呢?不妨再实践中进行解答。
There are a total of n courses you have to take, labeled from 0 to n - 1.
Some courses may have prerequisites, for example to take course 0 you have to first take course 1, which is expressed as a pair: [0,1]
Given the total number of courses and a list of prerequisite pairs, return the ordering of courses you should take to finish all courses.
There may be multiple correct orders, you just need to return one of them. If it is impossible to finish all courses, return an empty array.
For example:
2,[[1,0]]There are a total of 2 courses to take. To take course 1 you should have finished course 0. So the correct course order is [0,1]
4,[[1,0],[2,0],[3,1],[3,2]]There are a total of 4 courses to take. To take course 3 you should have finished both courses 1 and 2. Both courses 1 and 2 should be taken after you finished course 0. So one correct course order is [0,1,2,3]. Another correct ordering is[0,2,1,3].
解题的思路很简单,有向图的环路检测+拓扑排序即可。接下来用上面介绍的两个方法给出AC代码。
1、贪心方法AC代码及详细注释
class Solution {
public:
vector<int> greedy(vector<vector<int>>&od,vector<int>&id){
stack<int>st;//辅助栈
vector<int>res;//保存拓扑排序的结果
for(int i=0;i<(int)id.size();i++){
if(!id[i]){//如果节点i的入度为0
st.push(i);//压入栈
}
}
while(!st.empty()){
int v=st.top();//从栈中取出一个入度为0的点
st.pop();//弹出
res.push_back(v);//连接到res上构造拓扑排序
for(int &i:od[v]){
id[i]--;//使节点v的邻接节点的入度都减少一
if(!id[i]){//如果v的邻接节点的入度为0
st.push(i);//则压入栈
}
}
}
return res.size()==id.size()?res:vector<int>();//如果最后还存在入度大于0的节点,表示此图存在环路,不存在拓扑排序
}
vector<int> findOrder(int nc,vector<pair<int, int>>& pre) {
vector<int>id(nc,0);//保存每个点的入度
vector<vector<int>>od(nc);//保存每个点指向的点的集合
for(int i=0;i<(int)pre.size();i++){
id[pre[i].first]++;
od[pre[i].second].push_back(pre[i].first);
}
return greedy(od,id);
}
};
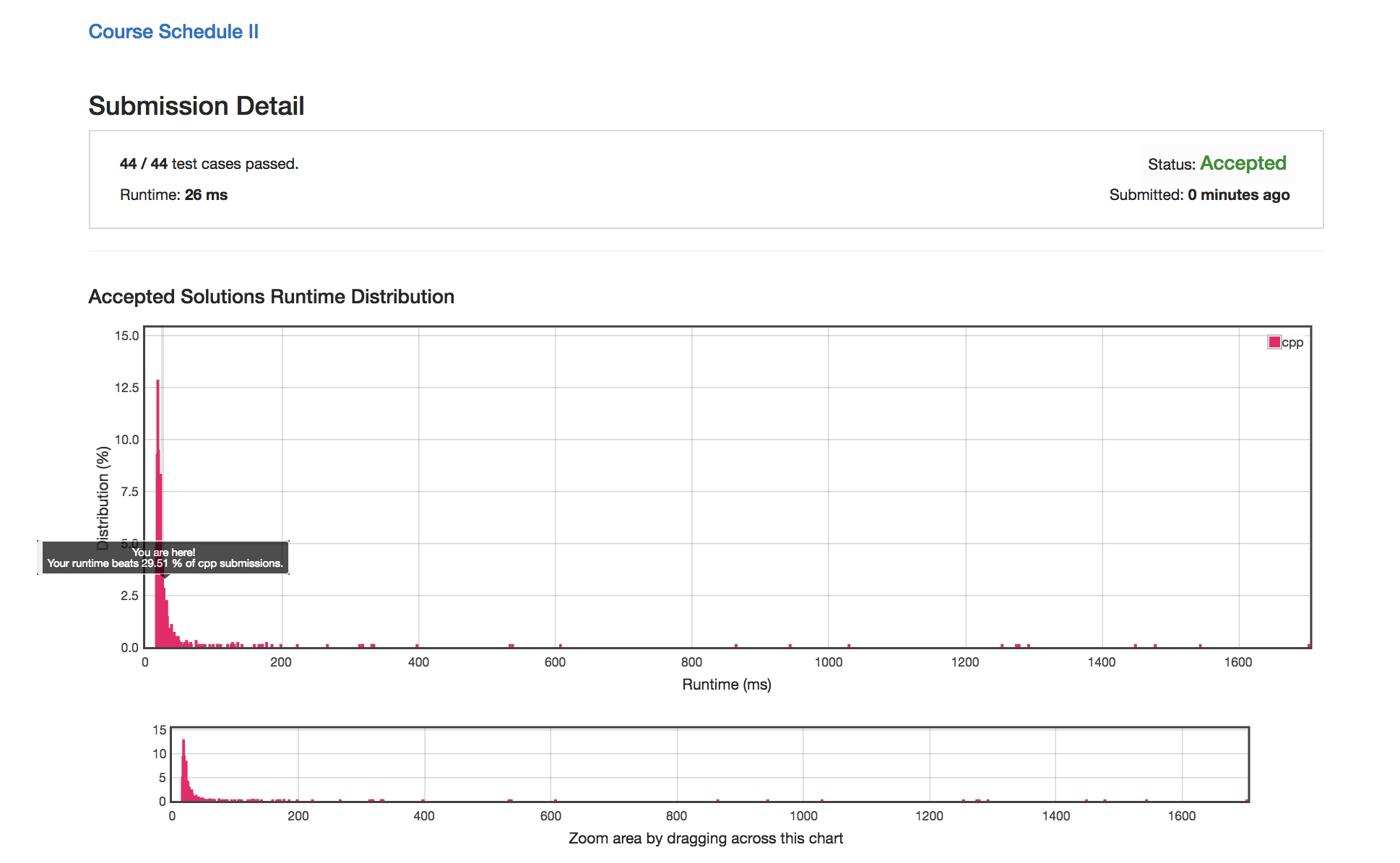
提交结果:26ms
2、基于深度优先搜索的代码(超时)
class Solution {
public:
void dfs_improve(int v,vector<vector<int>>&od,vector<int>&visited,stack<int>&st){//基于深度优先搜索的拓扑排序
visited[v]=1;
for(int &i:od[v]){
if(!visited[i]){
dfs_improve(i,od,visited,st);
}
}
st.push(v);
}
bool dfs_loopcheck(int v,vector<vector<int>>&od,vector<int>visited){//环路检测
visited[v]=1;
for(int &i:od[v]){
if(!visited[i]){
bool res=dfs_loopcheck(i,od,visited);
if(res)return true;
}else return true;
}
return false;
}
vector<int> findOrder(int nc,vector<pair<int, int>>& pre) {
vector<int>visited(nc,0);//访问标记
vector<vector<int>>od(nc);//用于保存邻接节点的集合
stack<int>st;//辅助栈
for(int i=0;i<(int)pre.size();i++){
od[pre[i].second].push_back(pre[i].first);
}
vector<int>res;
bool loopcheck=false;
for(int i=0;i<nc;i++){//检查环路
if(dfs_loopcheck(i,od,visited)){
loopcheck=true;
break;
}
}
if(loopcheck)return res;
for(int i=0;i<nc;i++){//找出拓扑排序
if(0==visited[i]){
dfs_improve(i,od,visited,st);
}
}
while(!st.empty()){
res.push_back(st.top());
st.pop();
}
return res;
}
};
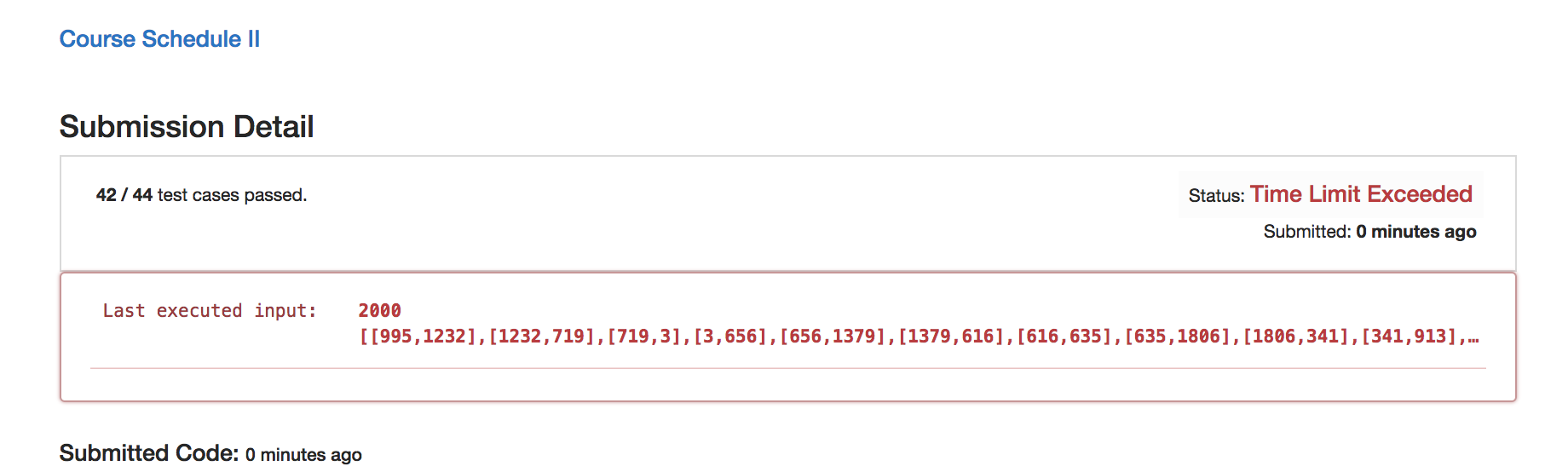
超时的主要原因在于检测环路的成本太高,要对每一个节点进行一次深度优先搜索。
3、基于深度优先搜索的代码(环路检测优化)
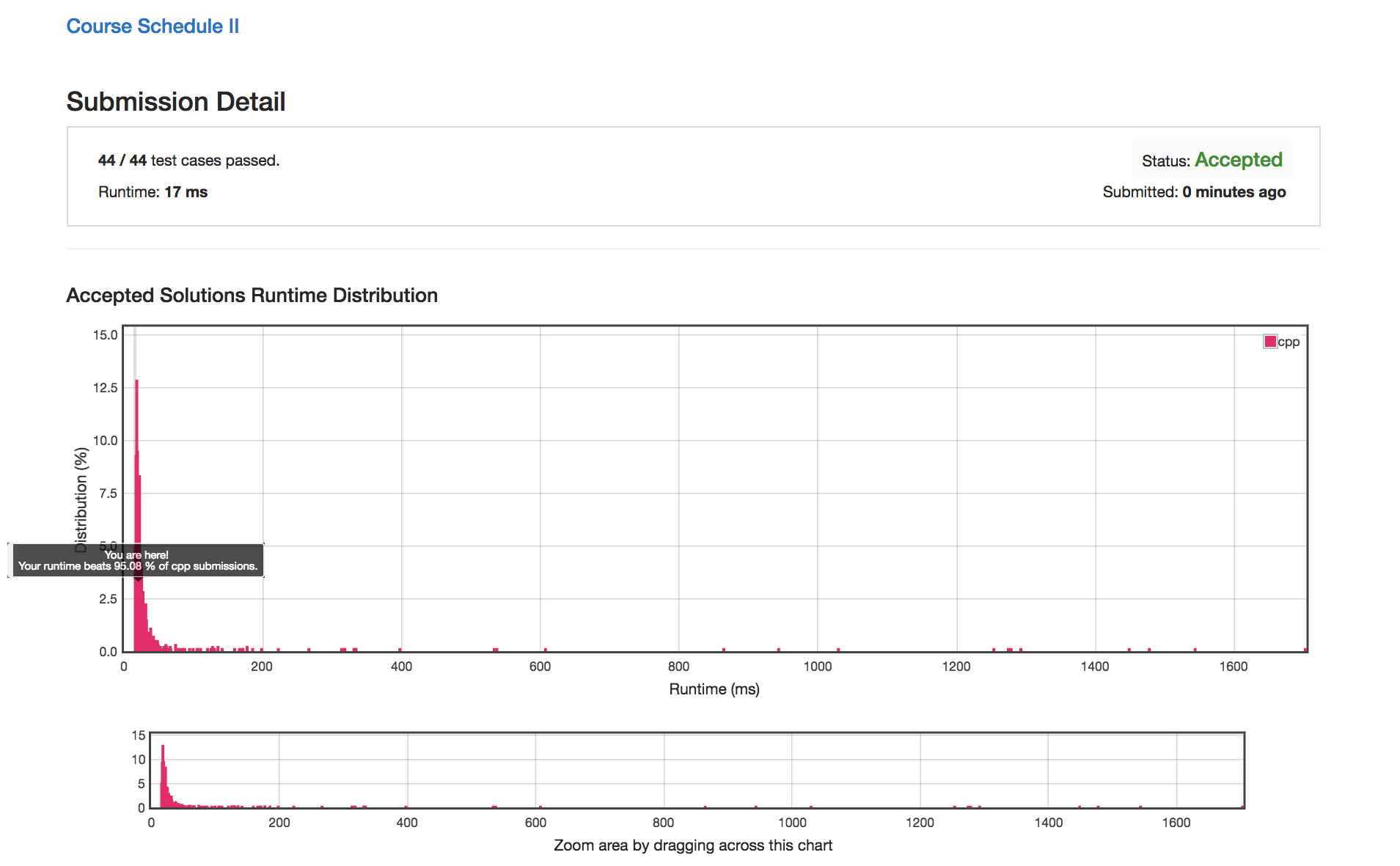
利用两个节点标记对深度优先访问的节点进行检查,保证在所有节点最多访问一次的情况下检测出是否存在环路,极大地节省了深度优先搜索检查环路是否存在的成本。使得原本超时的方法成为速度最快地方法(16ms,快于95%的提交),详细思路见注释。
class Solution {
public:
bool dfs_improve(int v,vector<vector<int>>&od,vector<int>&visited,vector<int>&loopvisited,stack<int>&st){
visited[v]=1;//标记访问过的节点,到一个点,标记一个点
for(int &i:od[v]){
if(!loopvisited[i]&&visited[i])return true;//如果loopvisited没有标记为访问,但visited却标记为访问了,表示这个节点在本次深度优先搜索时已经访问过,即存在环路。
if(!visited[i]){
bool loopcheck=dfs_improve(i,od,visited,loopvisited,st);
if(loopcheck)return true;
}
}
loopvisited[v]=1;//标记访问过的节点,但到整个深度优先搜索结束后才标记,所以loopvisited已作标记的是之前本次搜索之前就访问过的节点。
st.push(v);
return false;
}
vector<int> findOrder(int nc,vector<pair<int, int>>& pre) {
vector<int>visited(nc,0);//访问标记
vector<int>loopvisited(nc,0);//环路检测访问标记
vector<vector<int>>od(nc);//每个点的邻接点集
stack<int>st;//辅助栈
for(int i=0;i<(int)pre.size();i++){
od[pre[i].second].push_back(pre[i].first);
}
vector<int>res;//用于保存拓扑排序
bool hasloop=false;//是否存在环路
for(int i=0;i<nc;i++){
if(0==visited[i]){
if(dfs_improve(i,od,visited,loopvisited,st))hasloop=true;//DFS(改良)
}
}
if(hasloop)return res;//如果存在环路,返回空集
while(!st.empty()){//构造拓扑排序
res.push_back(st.top());
st.pop();
}
return res;
}
};
提交结果16ms:
推荐阅读:
图论的各种基本算法PS:
广告时间啦~
理工狗不想被人文素养拖后腿?不妨关注微信公众号:


我们在微信上24小时期待你的声音
解答本文疑问/技术咨询/运营咨询/技术建议/互联网交流
微信二维码
移动版官网

