扫二维码与项目经理沟通
我们在微信上24小时期待你的声音
解答本文疑问/技术咨询/运营咨询/技术建议/互联网交流

在数据库中,优化器之所以重要,是因为SQL是一种声明式的语言,只是告诉用户需要什么数据,但获取数据往往有多条路径,路径间代价差异可能会很大,优化器则是负责快速、高效的找出获取数据的最佳执行路径,是数据库的大脑,可谓得优化器者得数据库天下。
论文An Overview of Query Optimization in Relational Systems写于1998年,虽然古老,但切实抓住了70年代以来的优化器的要点,综述了2种优化器框架,System-R(bottom-up)和Cascade(top-down)。到目前为止,主流关系型数据库优化器是基于这两种框架演进而来的。主流数据库优化器框架如下:
本文将尝试对结合主流优化器的工程实现,对相关的技术原理进行一次总结。
论文提出,对于SQL数据库系统,最重要的两个组件是Query Optimizer和Query Execution Engine。
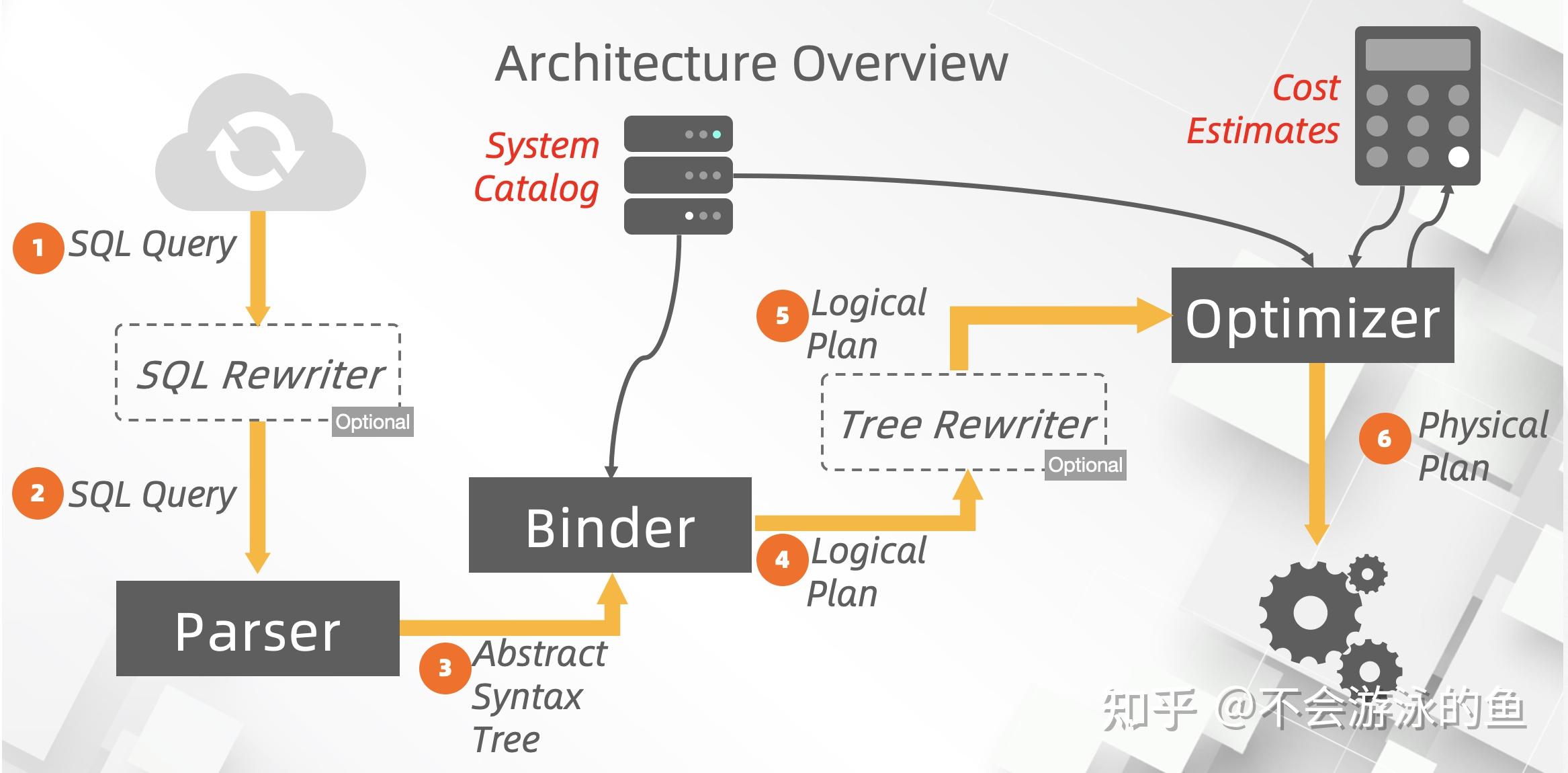
上图是cmu给出的优化器架构图,重点是逻辑计划(Logical Plan)和物理计划(Physical Plan)。在Optimizer模块,根据输入的逻辑计划、统计信息、代价评估模型,生成代价最低的物理计划,将物理计划传入给Execution Engine(执行器),由执行器负责执行。一般情况下,在对SQL Query语法解析后,会根据启发式规则,进行Query rewrite,例如,过滤下推,生成一个唯一的逻辑计划。然后再以这个逻辑计划为输入,根据关系代数等价变换规则,生成多种等价的逻辑计划,结合代价评估模型,生成对应的物理计划,最终,选择代价最低的,发给执行器。
这里简单解释下
论文认为优化器应该提供三个组件
System-R框架的主要流程是
个人理解,论文中表达System-R框架的三个主要贡献点如下:
在具体实现中
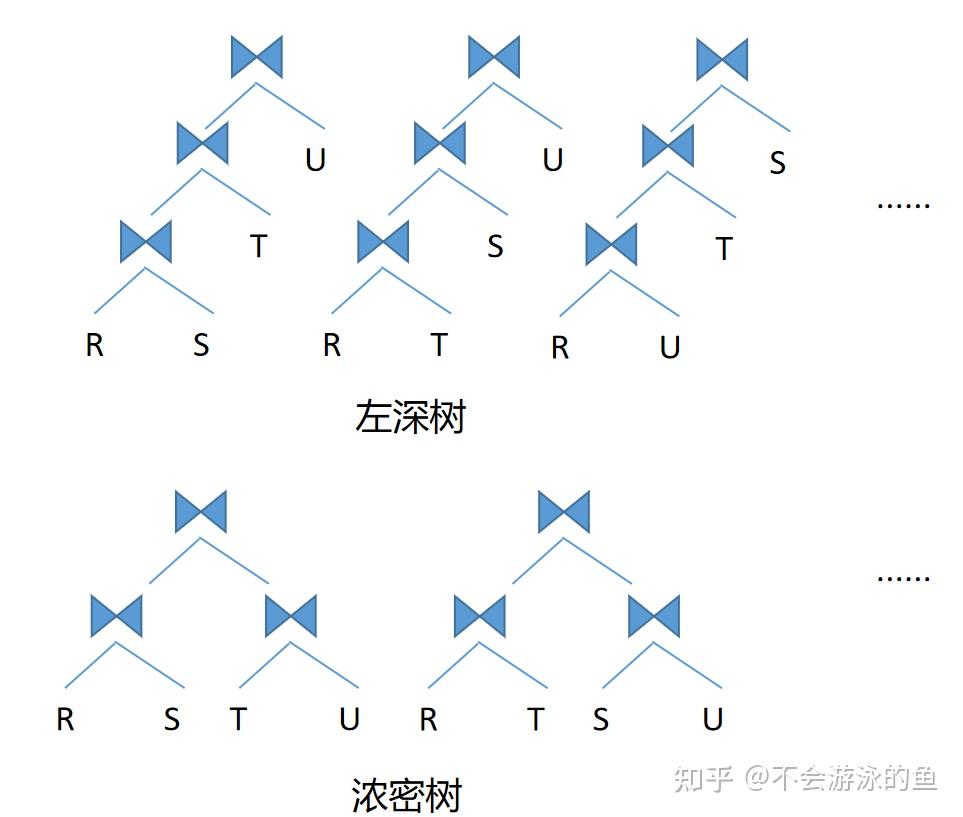
这里实际上是包含2部分,统计信息和个算子的代价评估模型。
(1)统计信息
统计信息一般包括统计信息收集和统计信息计算2个环节,在System-R框架和Cascade框架中是通用的。业界产品实现说明如下:
【1】StarRocks 统计信息
统计信息(Statistics Class) 描述了表中数据的详细信息,包含表的行数和每一列的数据分布:最大/最小值,不同值的个数(NDV),NULL 值个数和列的平均大小(Average Row Size)。 因此整体流程可以大致分为两部分,分别是统计信息的收集和统计信息的读取计算。
下图描述了统计信息的收集和读取计算的整体流程:
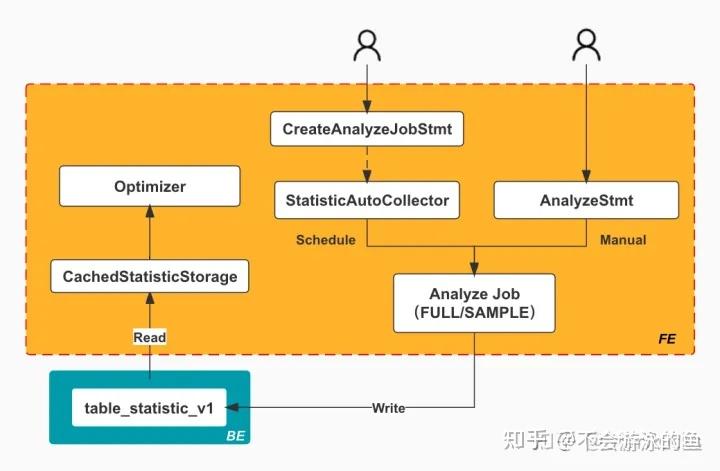
统计信息的收集包括手动和定期任务这两种触发方式,对应了图中的两种 Statement :CreateAnlyzeJobStmt(创建 Analyze 定期任务)和 AnalyzStmt(手动执行 Analyze 命令)。两种方式都会创建一个 AnalyzeJob,由它负责具体的统计信息的收集,收集的类型包含全量(FULL)和抽样(SAMPLE)两种。
AnalyzeJob 在执行具体的收集任务时,首先会创建多个 TableCollect Job。而每个 TableCollect Job 又会负责收集对应 Table 的统计信息,收集过程中还会使用 StatisticsExecutor 来负责实际的统计信息的写入。如下图所示:
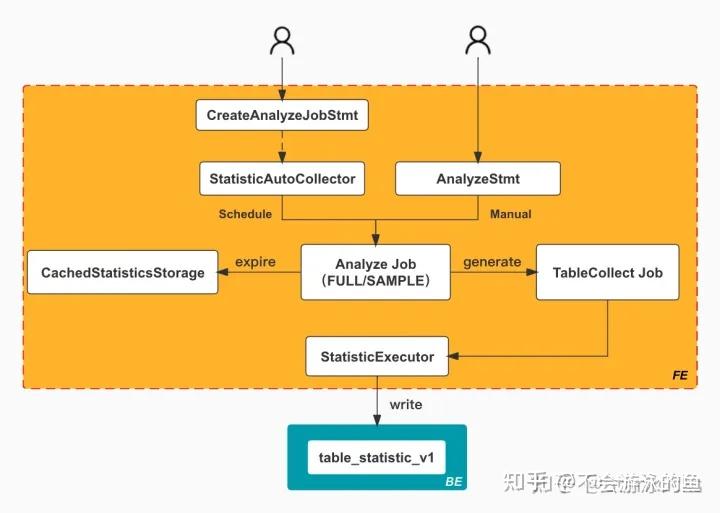
而收集到的统计信息会存储在 BE 的 _statistics_.table_statistic_v1 表中。其中记录了不同 table 每一列的统计信息,如下图所示:

读取的整体流程比较简单,Optimzier 会首先从 CachedStatisticStorage 中读取,如果 cache 中没有对应的统计信息,则会从 table_statistic_v1 表中读取对应列的信息。
本段内容来源:StarRocks 统计信息和 Cost 估算
【2】CockroachDB 统计信息
整个流程与StarRocks 相似,包括自动或手动创建表的统计任务,执行任务并收集信息。
流程图如下:
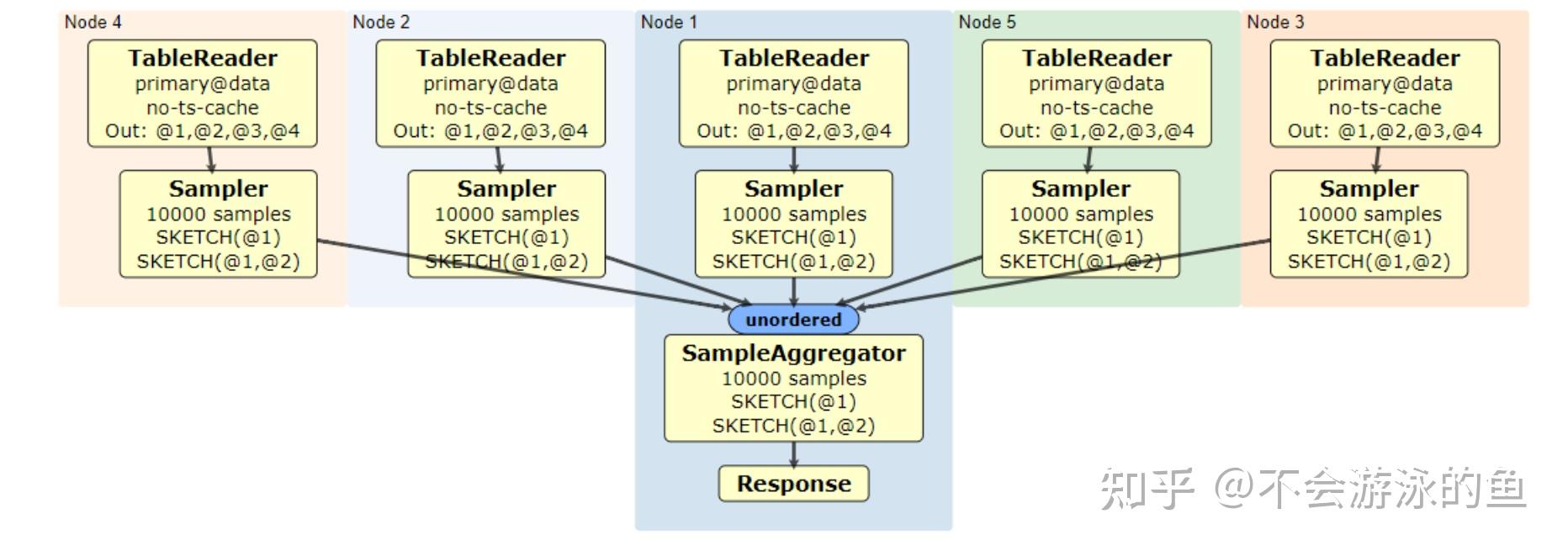
https://github.com/cockroachdb/cockroach/blob/master/docs/RFCS/20170908_sql_optimizer_statistics.md
(2)代价评估
代价评估模型使用bottom-up方式进行计算:
【1】单机代价评估
总代价=IO代价 + CPU代价
注:有些实现中,也会考虑内存代价
例如,单表扫描代价模型
顺序扫描:N_page * a_page_IO_time + N_tuple * a_tuple_CPU_time
索引扫描:C_index + N_tuple_index * a_tuple_IO_time
来自:《数据库查询优化器的艺术》
【2】分布式数据库代价评估
对比单机,需要增加的是数据重分布代价,这点非常重要。因为查询重写可能会改变数据原有的分布,例如 join、group等数据聚集操作,这需要评估那个表的数据、多少数据需要在网络中重分布。
以SingleStoreDB(MemSQL)为例,进行说明。SingleStoreDB(MemSQL)是一款分布式HTAP数据库,利用内存优化、scal-out的架构来支持实时事务和分析工作负载,这些工作负载快速、高并发且具有极高的可伸缩性。
数据重分布主要包括两类:
注:R是待传送的tuple的数量,N为节点总数,D是单tuple网络传输的cost,H是单tuple hash evaluation cost。
CREATE TABLE T1 (a int, b int, shard key (b))
CREATE TABLE T2 (a int, b int, shard key (a),
unique key (a))
Q1: SELECT sum(T1.b) AS s FROM T1, T2
WHERE T1.a=T2.a
GROUP BY T1.a, T1.b
Q1可以通过group by算子下推重写
?
Q2: SELECT V.s from T2,
(SELECT a,
sum(b) as s
FROM T1
GROUP BY T1.a, T1.b
) V
WHERE V.a=T2.a;假设T1有R1=200000行,T2有R2=50000行,T1执行完group后剩余有S_G=1/4比例,即S_G * R1=50000行,执行完Join剩余S_J=1/10,即S_J * R1=20000行,那么Group和Join执行完剩余R1 * S_G * S_J=5000行。
假设T2.a索引单点查询代价为每行C_J=1,Group By通过hashtable实现,代价为每行C_G=1,那么:
MemSQL优化器论文中给出的单表统计信息、代价评估方法如上(未考虑数据分布),计算出评估结果如下:

考虑数据分布的计算结果如下:因为T2按T2.a分区,但T1没有按T1.a分区,所以join需要移动数据,T1按T1.a做重分布或者广播T2,如果T2比较大,那么可能要选择重分布 T1。这种情况下Q1和Q2的代价情况可能就有所不同了。

关于SingleStoreDB(MemSQL)优化器的论文内容,可参见https://zhuanlan.zhihu.com/p/594101717
关于Interesting Order,在Andy教授上课的视频中,好像在说,“由于System-R在每个阶段都在寻找最优解,所以在使用单独的SM JOIN时,会陷入局部最优,无法找到最优解。”在这篇论文中,Interesting Order 被明确地写成 System-R 的一部分。
个人理解,在SQL Query中,可以从供需角度将Order分为两类,top-down的required order,bottom-up的interesting order。示例解释如下:
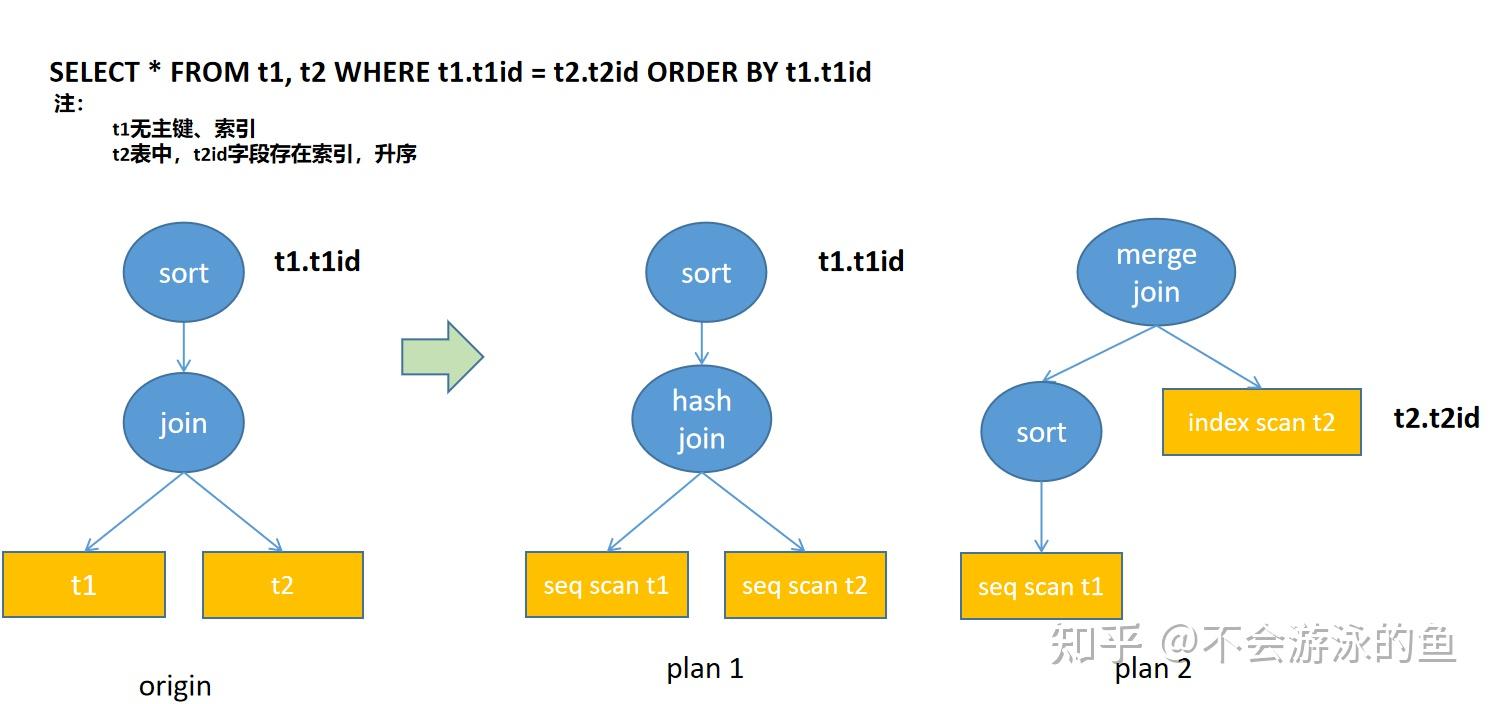
上例
plan1中,分别对t1和t2进行顺序扫描,然后进行hash join,join结果按照t1id进行排序。
plan2中,因为对t2进行index scan可以提供有序的结果,此时,在t1顺序扫描后,增加一个sort算子,对t1的rows按照t1id进行排序,最终采用merge join的算法进行合并。
这种通过interesting order的方式,扩展了plans集合,后续可以根据代价评估选择最佳plan。
算法简介
补充说明
示意图如下:

上图中,数字表示层树,第1层正方形表示关系表,第2层开始表示表的join关系

举例说明如下:
SELECT brand.name
FROM owner, car, brand
WHERE owner.name="Taro"
AND car.owner_id=owner.id
AND car.brand_id=brand.id 
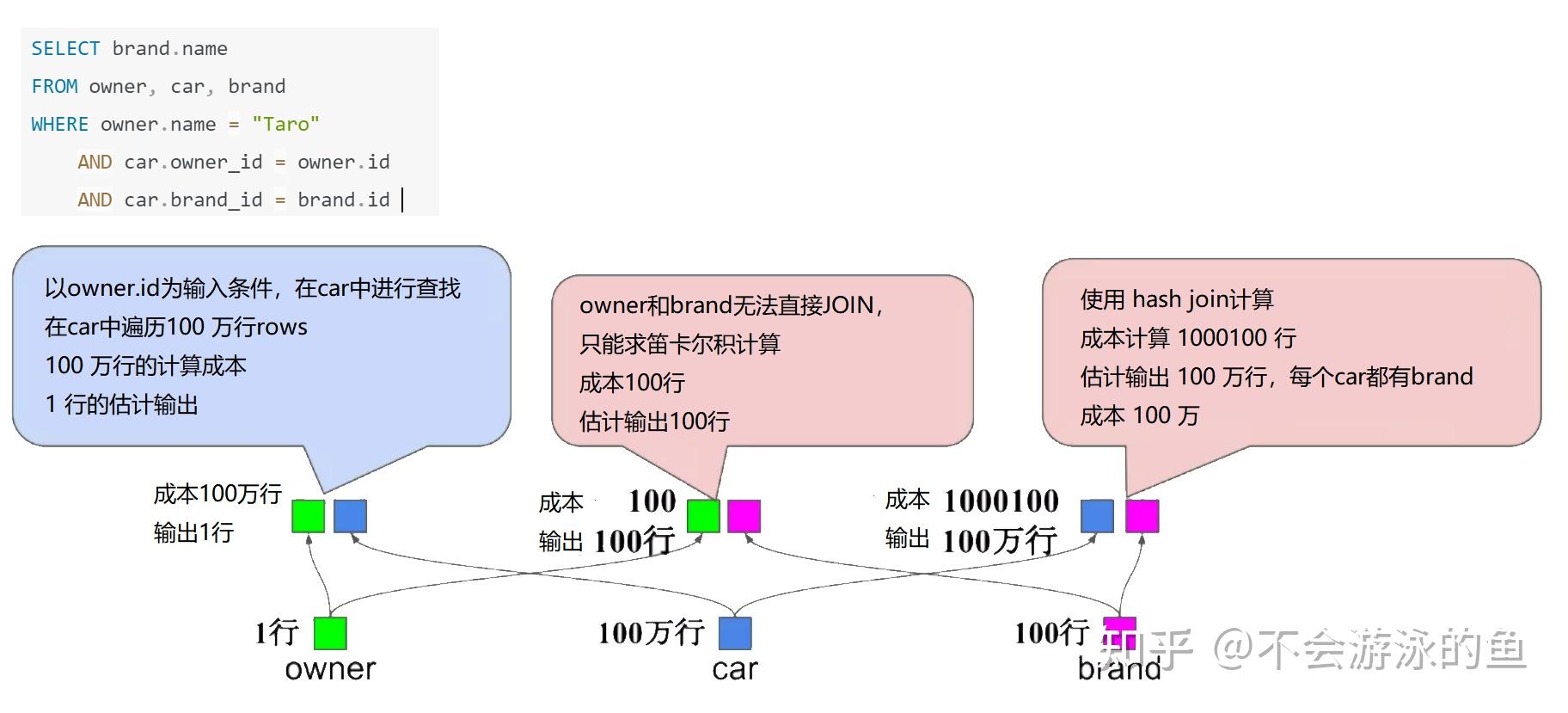
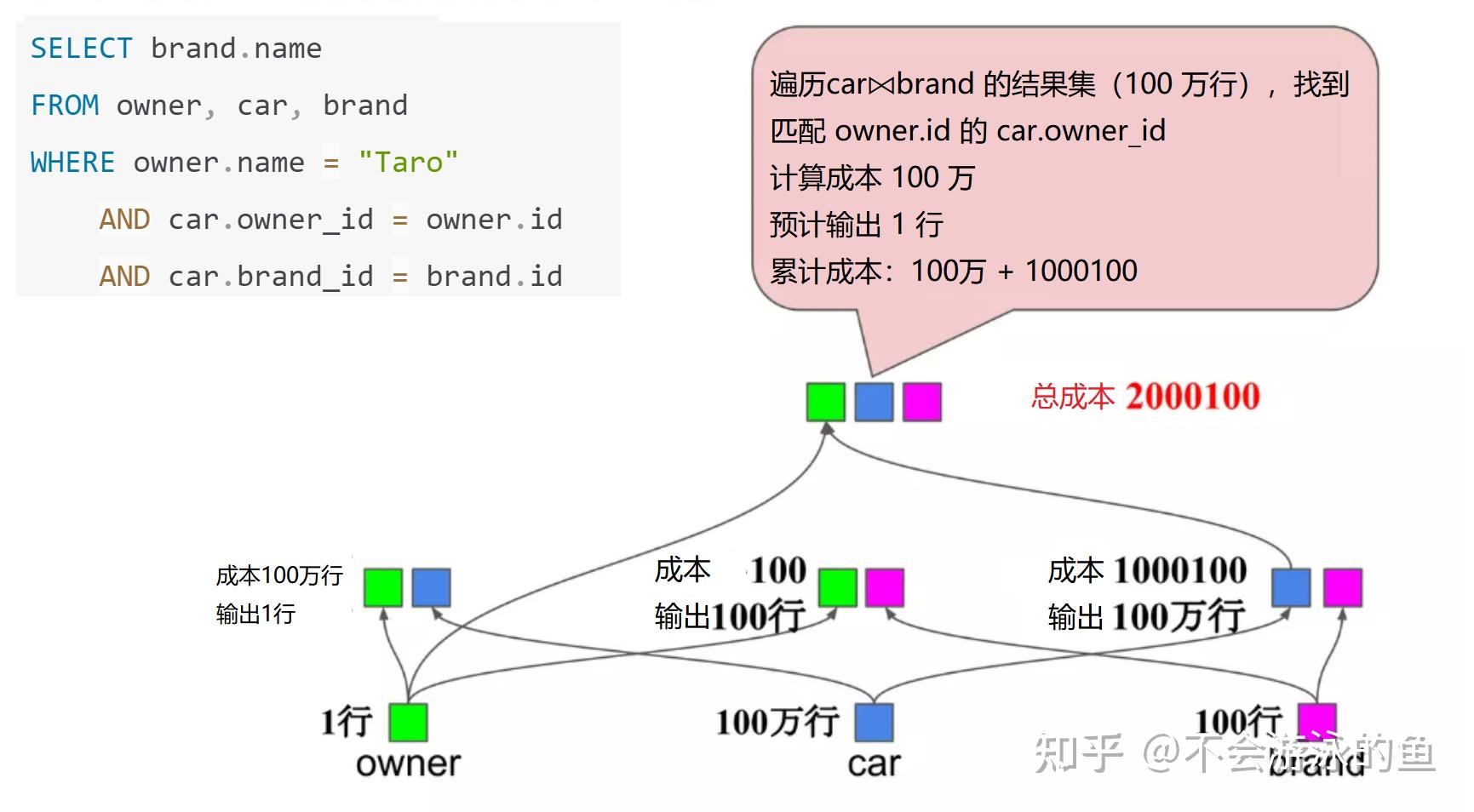
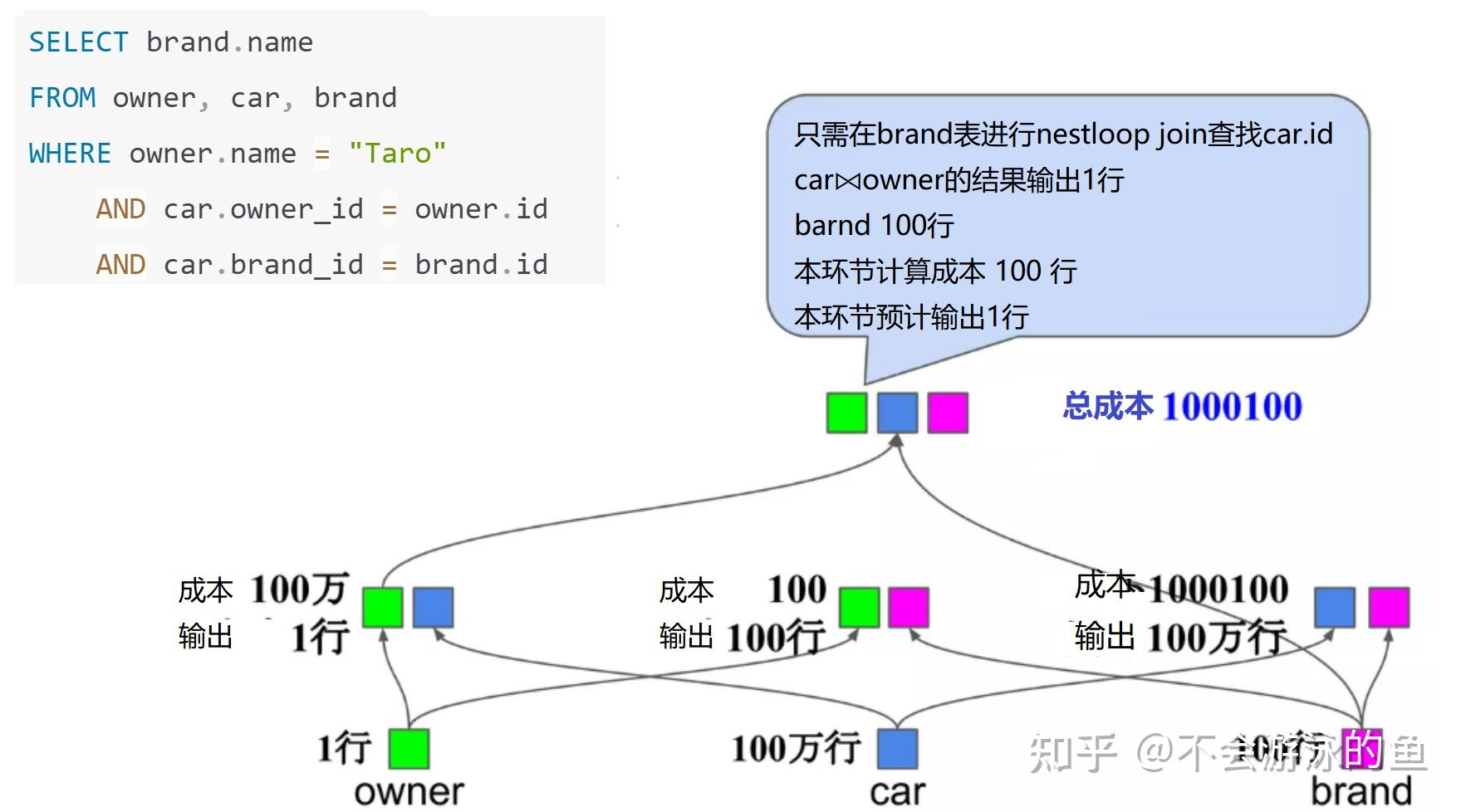
方案1计算成本,2000100,方案2计算成本1000100,因此方案2最佳。
注:DP示例引自https://www.slideshare.net/kumagi/an-overview-of-query-optimization-in-relational-systems
search space的理解:SQL是一种声明式的语言,只是用户告诉数据库我需要什么数据,在数据库系统中,为了读取目标数据可以生成多少种plan,这个plan的集合,就是搜索空间。通俗点理解,类似于从北京去上海,使用导航软件,能够查询到的路线的集合。
数据库生成plan集合主要基于2个能力,一是transform的能力,也就是说基于关系代数理论和经验规则,进行逻辑变换的能力,一个input plan能够产生的逻辑上等价的plans的规模;二是代价评估,根据代价评估模型,统计信息,plan中各算子提供的实现算法,从plans中快速找到最优的计划。
优化器要做的事情是尽可能多的生成plan高质量集合,尽可能快的找到最佳计划。实现的基本流程是sql query -> parser(得到语法树)->tree rewrite (得到唯一的operator tree) ->transform (关系代数等价变换,得到等价的plans)-> 代价评估(最佳的执行计划tree,仅1个)->Execution Engine执行。
基于当时的实际情况,作者给出了优化器实现的两个代表,基于System R框架的Starburs,EXODUS优化器框架(Volcano/Cascade是在EXODUS的基础之上优化而来)。不过论文并没有给出Starburs和EXODUS的框架机制,这里补充介绍下:
Starburst项目主要是针对于Query Rewrite模块,创新的提出了实现一套可扩展的Rule Engine来更好的实现逻辑关系代数转换,DB2的优化器核心思想来自于System R和Starburst。在Starburst会根据SQL query生成QGM(抽象语法树),经过优化器,生成QEP(执行计划树),简单说明如下,进一步信息可以参见[SIGMOD 1996]Fundamental Techniques for Order Optimization 论文学习
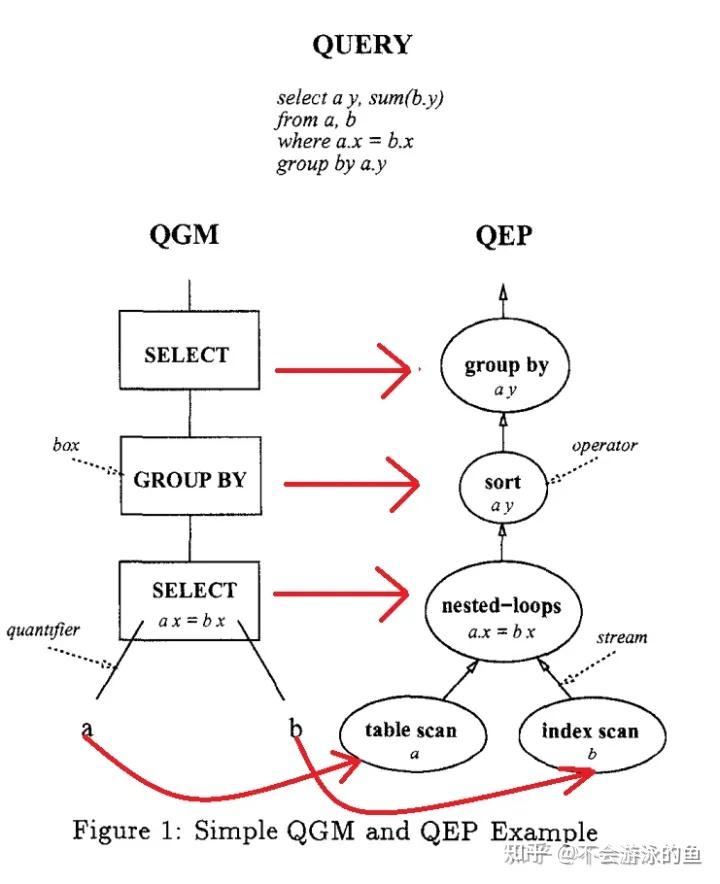
示例说明如上图1所示。图中左侧为Query对应的QGM(抽象语法树),右侧为QEP(执行计划树)。
EXODUS是一个可扩展的数据库,目标是为了帮助数据库的实现者快速实现高效的、应用特定的数据库系统,可以独立于数据模型,提供核心的组件包括通用的存储管理器和类型管理器,并提供了一套通用架构、工具和组件,有兴趣可以参考《The Architecture of the EXODUS Extensible DBMS》。
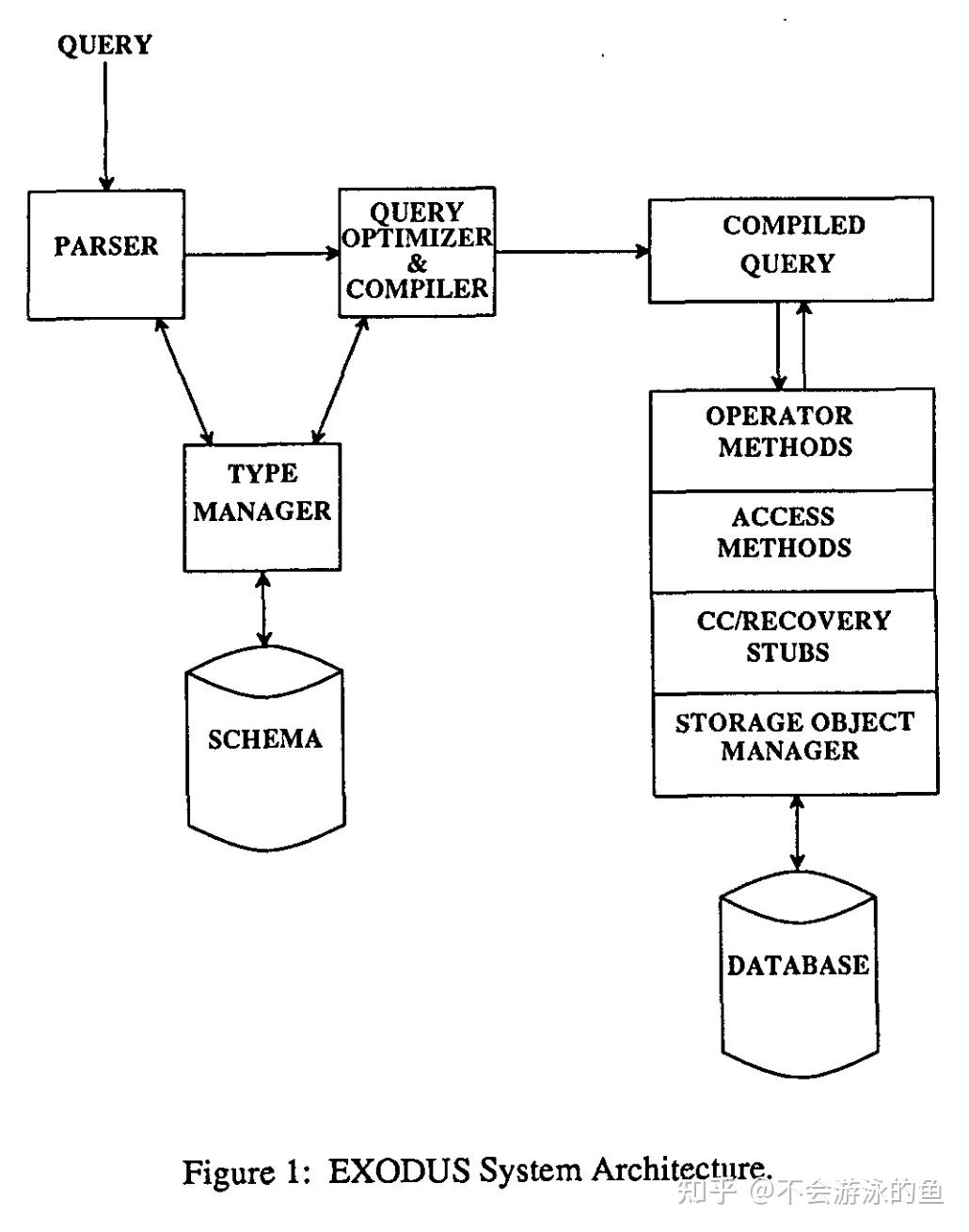
下面是EXODUS Optimizer Generator的架构图,输入是和查询树转换相关的一组算子、一组方法实现和关系代数转换规则及算子和方法实现之间的描述信息(model description file)。
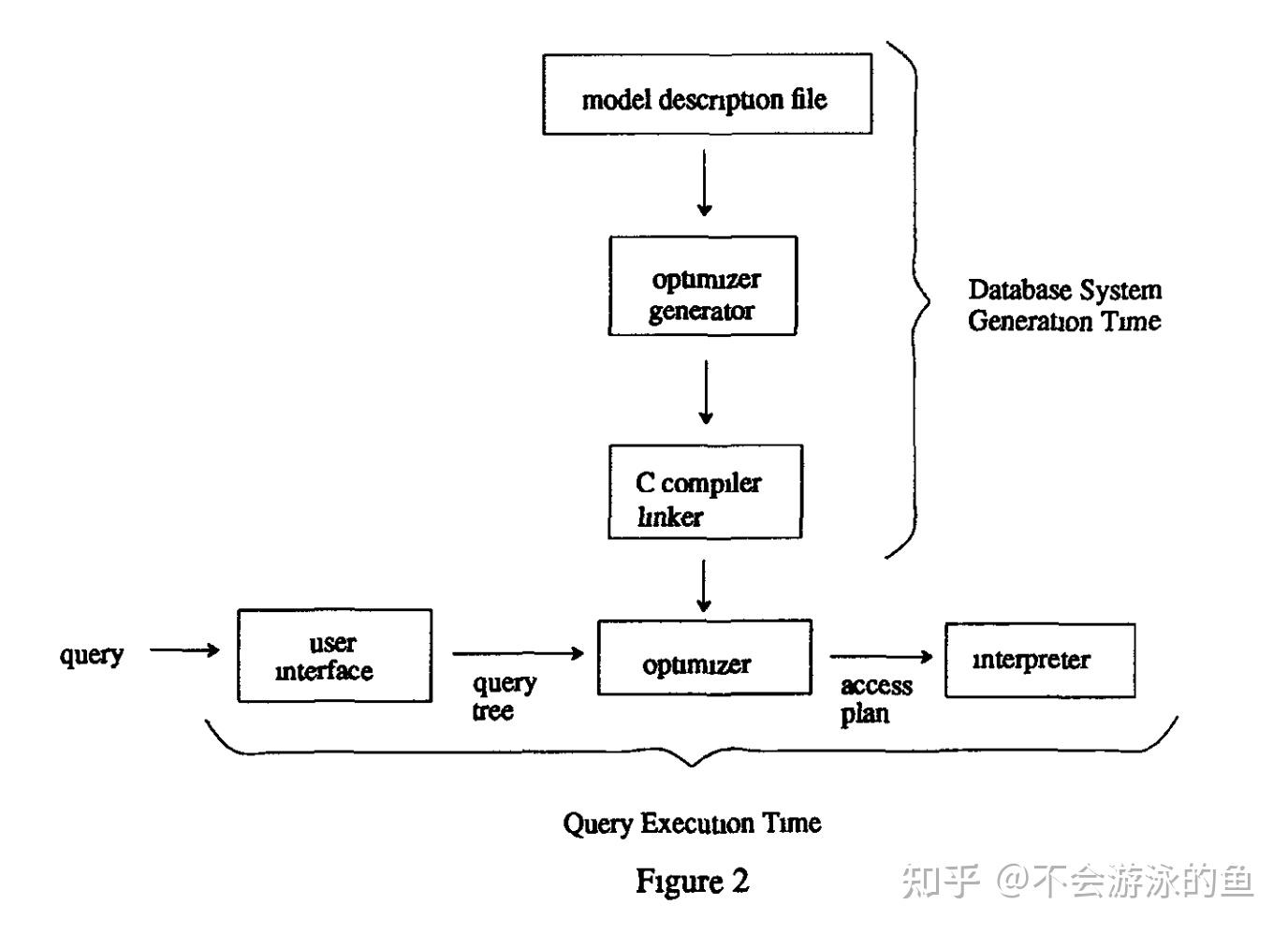
注:上述EXODUS的介绍来自https://developer.aliyun.com/article/1060881#slide-8。
Volcano/Cascade框架是在EXODUS基础上演进而来的,目前已有很多优秀代表,例如TiDB、Greenplum Orca、CockroachDB、PolarDB-X、PolarDB PostgreSQL引擎、GreenPlum-Orca、TiDB、Apache Calcite、Apache Doris、StarRocks等。不过这些数据库优化器实现中,仅CockroachDB基于DSL语言的model description file和内置的优化器生成工具,在数据库编译时,生成优化器代码,而后用于整个数据库的编译。其他数据库,都是采用了面向对象的思想,提供了transform rules的注册机制,直接用C++、Java、Go等开发rule的实现。
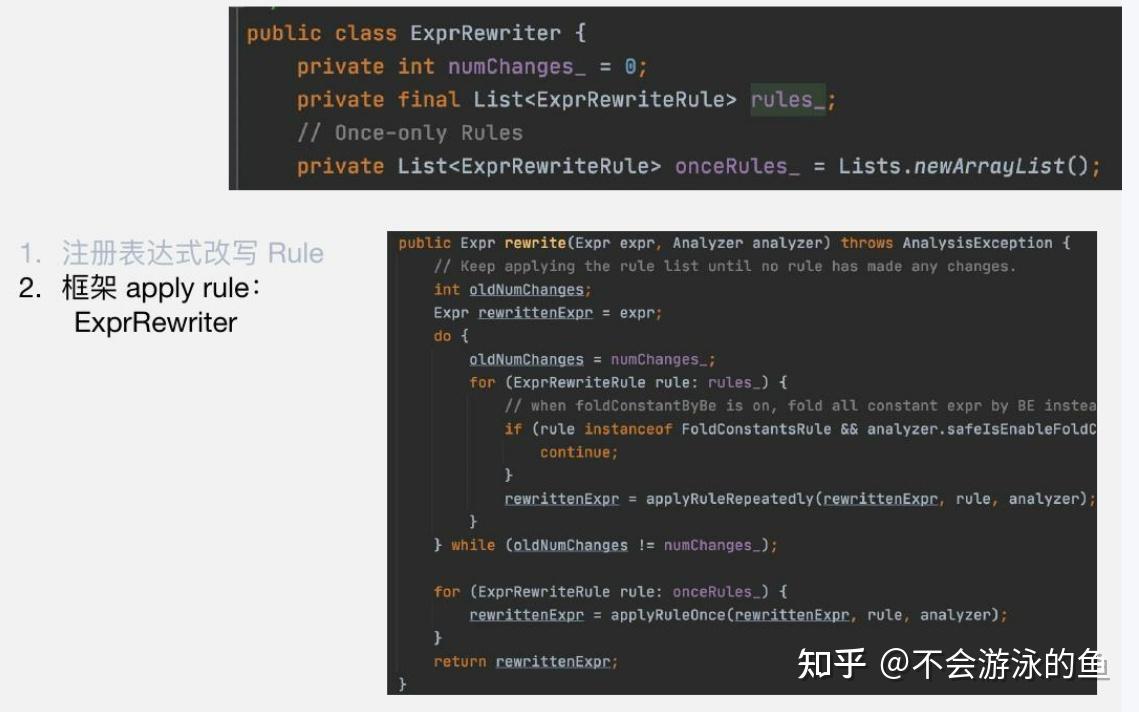
Apache Doris transform rules注册使用机制如下(https://www.slidestalk.com/doris.apache/doris75626):

CockroachDB DSL规则如下:
DSL: Optgen
# 如果input expr满足 not (not expr)形式,则去掉not,直接则返回input expr
[EliminateNot, Normalize]
(Not (Not $input:*))=>
$inputCockroachDB DSL规则编译后的go代码
// 本段代码有优化器生成器根据DSL生成
// 例如,input expr为 not (not a),此时输入参数input为‘not a’,方法的返回值为a,非常简单
func (_f *Factory) ConstructNot(input opt.ScalarExpr) opt.ScalarExpr{
//[EliminateNot]
{
_not, _ :=input.(*memo.NotExpr)
if _not !=nil{
input :=_not.Input
if _f.matchedRule==nil || _f.matchedRule(opt.EliminateNot){
_expr :=input
return _expr
}
}
}
// ... other rules ...
e :=_f.mem.MemoizeNot(input)
return _f.onConstructScalar(e)
}关于CockroachDB优化器的进一步信息,请参见CockroachDB优化器原理。
论文本节主要是介绍了一些基于关系代数的逻辑等价变换规则
从现在的视角看,还是存在很多局限性的,这里不做展开,后续有很多优秀的论文,提出了相关的高质量的算法,并且已经应用到Oracle、TiDB、PolarDB、Cockroach、Orca等产品中。
[SIGMOD 13]On the correct and complete enumeration of the core search space--学习
[VLDB 06]Cost-based query transformation in Oracle 论文学习
[ACM Trans'97]Outerjoin Simplification and Reordering for Query Optimization--论文学习
[SIGMOD '01]Orthogonal Optimization of Subqueries and Aggregation 学习笔记
plan考虑的代价评估要素(资源):
System-R代价估计框架如下:
对于一个plan,迭代的探索算子树的个结点的代价和总代价,估算完各算子的代价,就能通过递归方法,计算整个plan的总代价。
统计信息与代价评估的工程实现,可参见如下博文:
对于一个输入的SQL query,优化器会根据表的访问方法、Join reorder方法,构建搜索空间,即生成多个执行的plans,枚举算法需要遍历搜索空间,找到最优的查询计划。在工程实践中,System-R和Volcano/Cascades都需要具备可扩展性,以便于增加新的transform rules、cost mode、operators等。同时,使用规则引擎,使优化器能够根据transform rules产生新的operator trees。
关于这方面的工程化实现可见:
StarRocks:StarRocks 统计信息和 Cost 估算
[SIGMOD 13]On the correct and complete enumeration of the core search space--join reorder算法学习
https://www.slideshare.net/kumagi/an-overview-of-query-optimization-in-relational-systems
[SIGMOD 1996]Fundamental Techniques for Order Optimization 论文学习
Apache Doris源码阅读与解析第8讲《查询优化器讲解》
[VLDB 06]Cost-based query transformation in Oracle 论文学习
[ACM Trans'97]Outerjoin Simplification and Reordering for Query Optimization--论文学习
[SIGMOD '01]Orthogonal Optimization of Subqueries and Aggregation 学习笔记
[SIGMOD 2014]Orca: A Modular Query Optimizer Architecture for Big Data 论文阅读

我们在微信上24小时期待你的声音
解答本文疑问/技术咨询/运营咨询/技术建议/互联网交流
微信二维码
移动版官网

